

The Melting Point
We applied autoresearch to protein thermostability, giving AI agents two levels of freedom pitted against Bayesian optimization, and learned when intuition can synergize with exhaustion.

Can AI Design Better Architecture and Tune Hyperparameters More Efficiently Than Us?
Every machine learning (ML) model is governed by a set of choices made before training begins including but not limited to learning rates, regularization strengths, architectural configurations, and initialization schemes. These hyperparameters, typically tuned via a combination of search algorithm and research intuition, determine whether a model trains well or poorly, fast or slow, and whether it generalizes or memorizes. Getting them right is critical.
In this post, we explore whether AI agents can help automate hyperparameter tuning, and share what happened when we adapted this “autoresearch” framework to solving a research-level workflow in computational biology.
Over the past fifteen years, the ML field has developed increasingly sophisticated strategies for identifying optimal hyperparameters1.
Despite these advances, training a model effectively still requires significant practitioner intuition on which knobs matter, which interactions are worth exploring, and when to abandon a direction. This intuition takes years to develop and remains stubbornly difficult to codify.
But what if AI agents could acquire a compressed version of this intuition, drawing on the accumulated knowledge of the ML literature? Could they autonomously run experiments around the clock, reason over results, and iterate without human intervention? Could they match or even outperform a skilled researcher?
Andrej Karpathy recently showed this is not just a hypothetical. He reported that an autonomous agent, left to optimize his nanochat project for two days, discovered roughly twenty improvements to the model’s hyperparameters — sharpening attention scalers, adding missing regularization, fixing optimizer betas, tuning weight decay schedules — all stacking additively across approximately seven hundred experiments. The result: an eleven percent reduction in “time-to-GPT-2”, a benchmark measuring how quickly a training run reaches GPT-2-level performance. While these were not revolutionary breakthroughs, they were the kind of methodical adjustments a skilled researcher makes by hand, executed end-to-end by an agent.
We wanted to understand what it actually feels like to implement such a framework from scratch — where it breaks, how it degrades, and how much it can move the needle in computational life sciences.
We used protein thermostability as a testing ground and illustrated that agentic hyperparameter tuning was able to achieve lower test mean absolute error (MAE) using a model roughly 15x smaller than the current reference2.
Beyond adapting Karpathy’s original conceptual approach, we tested Bayesian optimization (BO) as a non-agentic baseline. We further framed agent autonomy as a spectrum rather than a switch, and introduced a hybrid framework that synthesizes LLM-agents and BO.
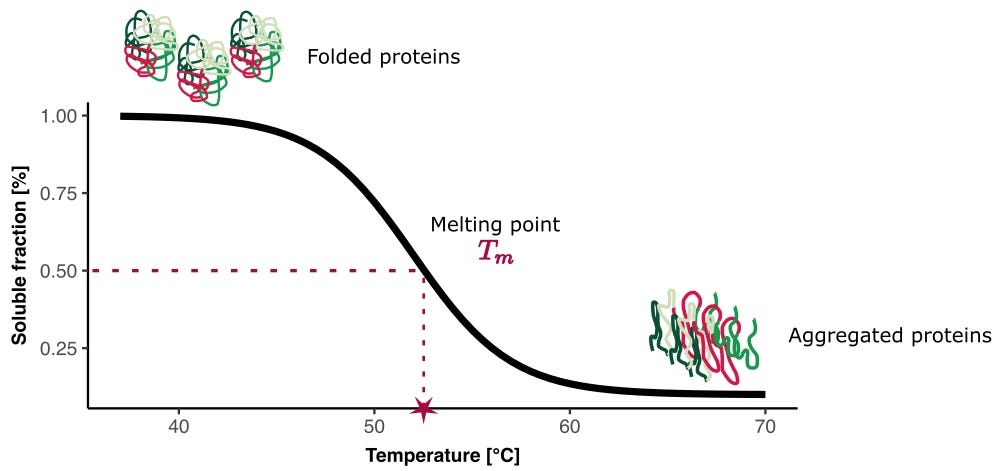
Proteins Melt and That Matters A Lot
Every protein has a melting temperature (Tm). Heat it past that threshold and the carefully folded three-dimensional structure unravels, hydrogen bonds break, hydrophobic cores become exposed, and what was a precisely shaped molecular machine becomes a disordered chain.
This temperature is the point at which both the folded and unfolded states are equally populated at equilibrium under the assumption of two-state protein folding.
A therapeutic antibody that denatures below 55°C cannot be formulated into a stable drug product. It will aggregate during manufacturing, degrade on the shelf, and lose activity before it ever reaches a patient. Thermostability correlates tightly with other drug developability properties — solubility, aggregation resistance, shelf life, and manufacturability. Developability properties separate a good molecule from a viable drug. Even the most potent and specific binder in the world is worthless if it falls apart at room temperature.
The computational biology community has concentrated much of its energy on binding affinity prediction (i.e., how tightly a drug grips its target), where standardized leaderboards, shared benchmarks, and competitions have driven rapid progress.
Thermostability prediction has received comparatively less attention, with fewer and smaller curated datasets and less systematic exploration from the ML community. From a reductionist lens, this problem is not overtly complicated. Tm can be reliably measured through experimentation and the readout is a positive scalar. All such properties made us choose melting temperature as a compelling first project for autoresearch in biology.
Before training a model, we need data. The Meltome Atlas is a proteome-wide thermostability dataset that contains melting curves for over 13,000 endogenous proteins across thirteen species in cell lysate. Unlike in vitro measurements on purified proteins in controlled buffer, this reflects thermal behavior closer to physiological conditions. TemBERTureDB builds on this by cleaning and curating the Meltome Atlas to produce a balanced dataset of thermophilic and non-thermophilic sequences. It partitions the data into train, validation, and test splits at an 80/10/10 ratio. To prevent data leakage and ensure balance, sequences were clustered by similarity and assigned to splits together. The train/validation/test sets were also balanced across the temperature range — oversampling rare melting temperatures and undersampling common ones.
Adapting Autoresearch Frameworks to Thermostability
We have set up our workflow to address the following task: given a protein’s amino acid sequence, predict its melting temperature. We evaluate primarily on mean absolute error (MAE) in degrees Celsius.
Our reference point is TemBERTure_Tm, introduced by the same authors behind TemBERTureDB, which reported an MAE of 6.42 °C in the test set. This model uses protBERT-BFD backbones fitted with an ensemble of Houlsby bottleneck adapters — roughly 25 million trainable parameters on top of a 420-million-parameter frozen backbone, a substantial model by any measure.
Our baseline model is compact by intention. We use frozen ESM-2 150M embeddings and attach a lightweight self-attention adapter plus a small MLP regression head: ~1.7 million trainable parameters — an order of magnitude smaller than TemBERTure_Tm.
This brings us back to the central question: given the desire to predict thermostability from protein sequence, how should we search for the best model? We consider five optimization approaches.
We start with Bayesian Optimization (BO) as the non-agentic baseline: it searches a fixed set of ~25 hyperparameters using a statistical model of the objective surface and proposes the next point to evaluate.
The agentic approaches span a range of freedom. At the one end, the Restricted Agent (RA) operates within the same ~25-knob search space as BO, but hands control to an LLM: the agent proposes 1–3 changes per trial, tracks its own history of successes and failures, and reasons through decisions like a careful researcher. Moving further along the spectrum, the Unleashed Agent (UA) drops all constraints. UA can rewrite the entire training script from scratch, inventing new architectures, loss functions, and training routines with no predefined structure.
Finally, we introduce two synthesis approaches that pair each agent with BO. RA + BO uses the restricted agent to reason about the search space and identify promising directions, then hands a reduced subspace to BO for exhaustive exploitation. UA + BO applies the same synthesis idea to the unleashed agent’s more open-ended proposals.
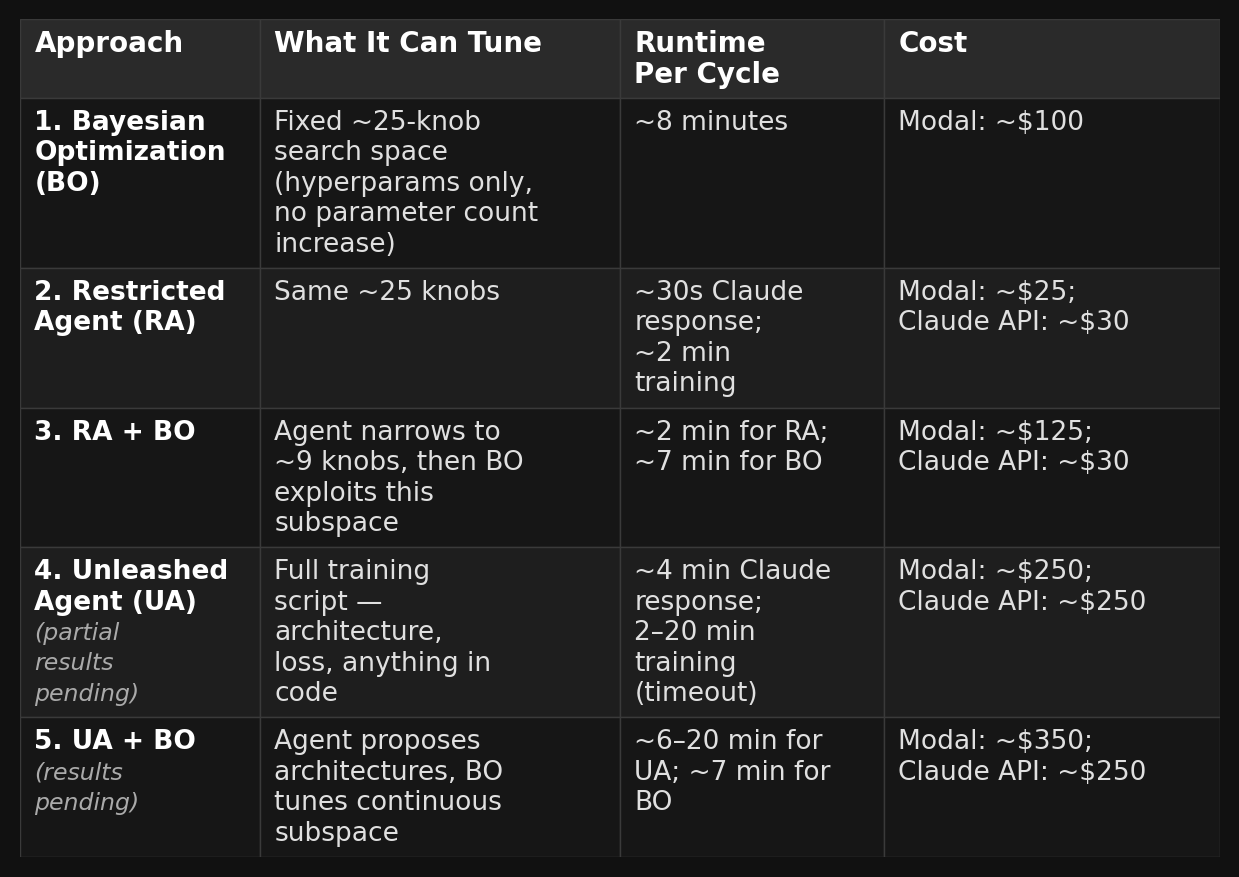
The first three approaches share the same fixed search space spanning architecture (attention heads, pooling, residual wiring, layer norm placement), training dynamics (learning rate schedule, optimizer hyperparameters, weight initialization), and loss function (MSE, Huber, MAE). Meanwhile, the unleashed agent’s only constraint is time.
The two synthesis approaches work like a scout and a surveyor, combining agent reasoning with Bayesian optimization’s exhaustive coverage of continuous subspaces. An LLM agent, our scout, makes methodical, interpretable changes but lacks precision on continuous variables. Bayesian optimization, our surveyor, is blind to structural reasoning but searches carefully through continuous spaces, filling every corner the agent would not have explored. Our framework pairs them: the agent operates in the outer loop, making high-level decisions about architecture and search space constraints; BO operates in the inner loop, exploiting the continuous subspaces the agent defines. This is the synergy we set out to test.
Results
To guard against overfitting to the validation set, we explicitly instructed the agents to be conscious of overfitting. For example, we instructed the model to inspect the val-train loss gap to make sure the model is not overfit to the validation data.
For each approach, we run 100 iterations with 3 replicates (dictated by 3 random seeds) per experiment. The random seeds control the stochasticity of the training processes. The agents are instructed to beat the current best on mean validation loss while maintaining strong performance in unseen test data.
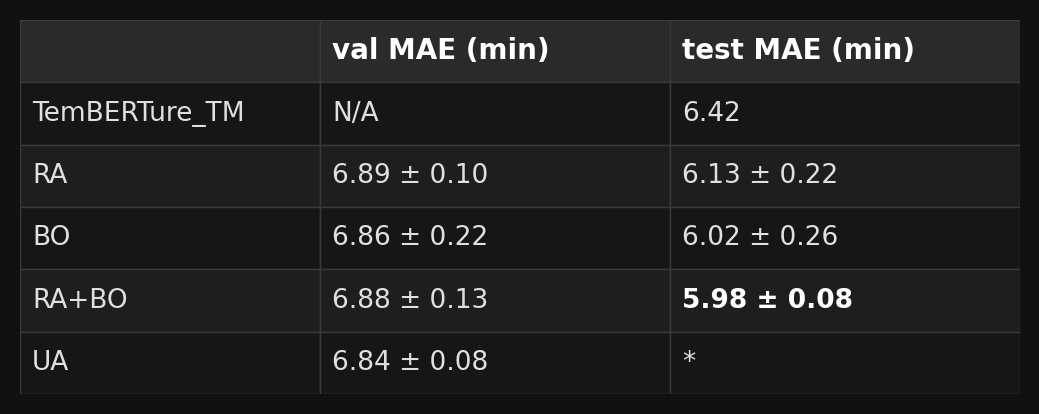
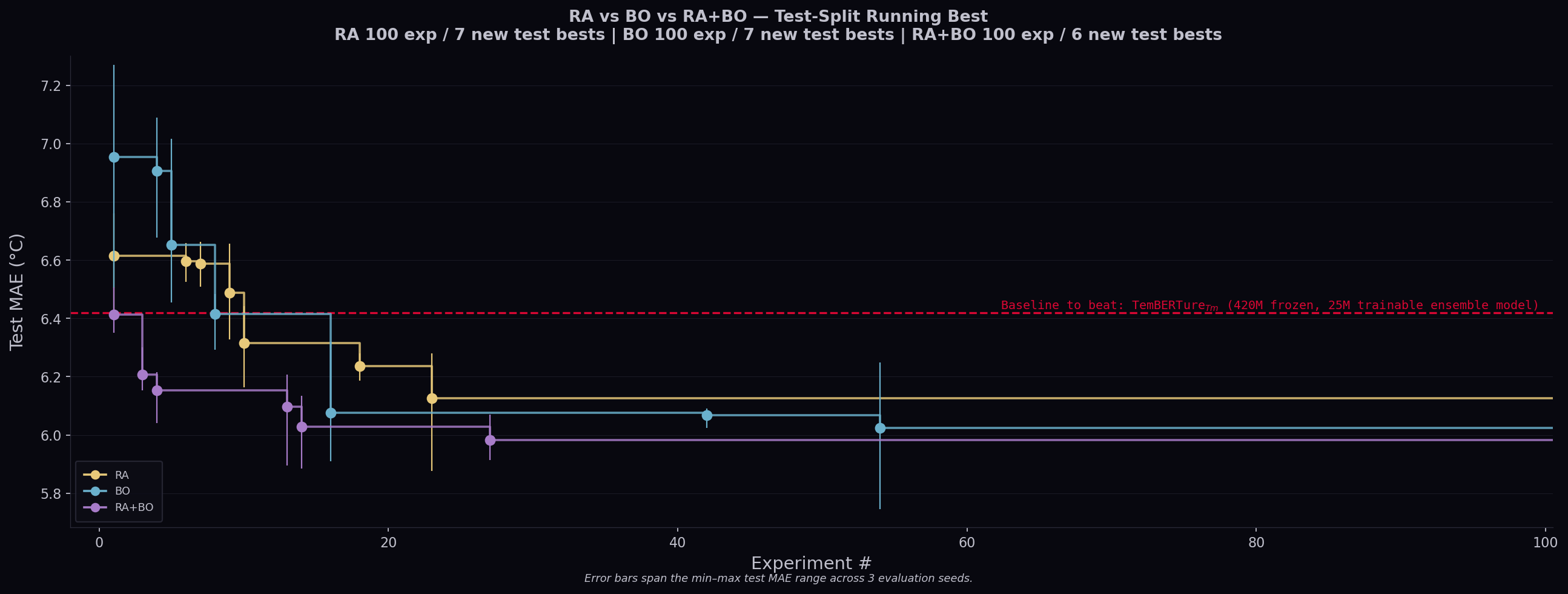
UA alone achieved the lowest validation MAE while RA+BO achieved the lowest test MAE. The results overlap substantially, and with only 3 replicates we cannot definitively claim which approach is best.
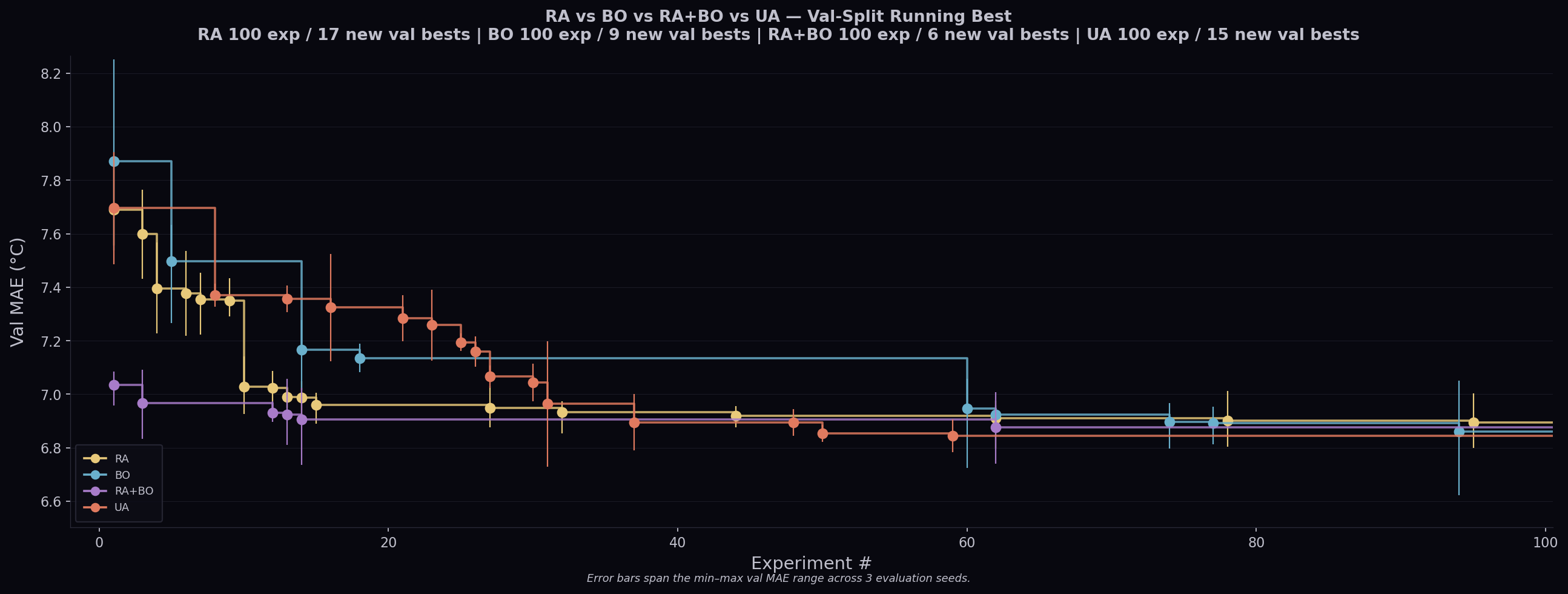
By tracking the running best, we notice the decrease in validation loss is correlated with decrease in test loss in general and all hyperparameter optimization methods were able to beat the baseline using a model roughly 15x smaller.
However, given the intrinsic stochasticity of model training and the fact that our test data is still an extremely limited representation of physical reality, we remain cautious about over-interpreting these numbers.
Agent Behavior: The Good, The Bad, and The Ugly
We intentionally seeded the starting configuration with a few suboptimal choices. The baseline used mean-pooling despite an available attention-pooling module that adds only 257 parameters, an aggressive early-stopping patience of 5 epochs (too short for this loss landscape), and MSE as the loss function even though we evaluate on MAE.
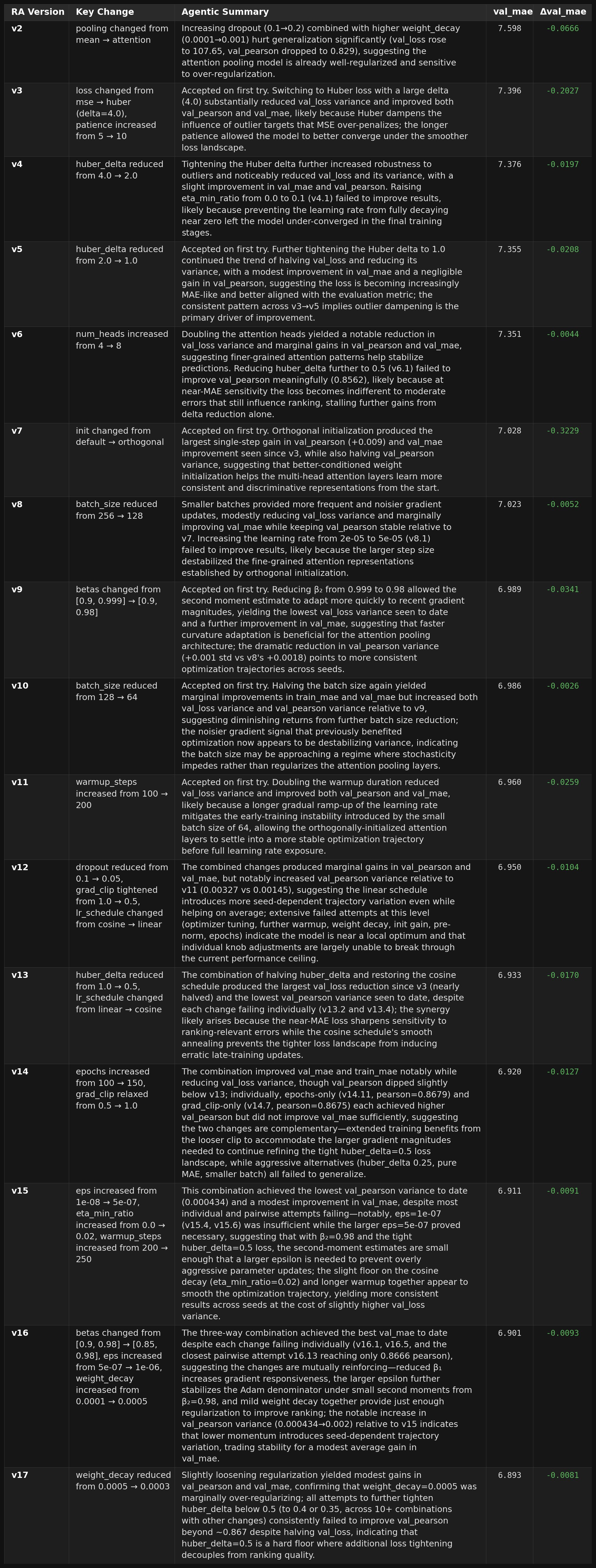
The RA was instructed to make 1–3 changes per trial, mimicking how a human researcher iterates. Its trajectory read like a textbook debugging session. First, it noticed the attention-pooling module sitting unused and switched to it. Next, it increased the early-stopping patience and swapped MSE for Huber loss in a single move: more room to navigate a rugged landscape, more robustness to outliers. It then increased attention heads (a well-known scaling lever up to certain point) and reduced batch size for better regularization. It also opted to orthogonal initialization which led to a large improvement.

At this point, we reached the best model based on test MAE. After these arguably intuitive and standard fixes, the agent moved into more esoteric territory such as optimizing hyperparameters and learning rate schedules where each change yielded only marginal gains. The result was steep early improvement followed by a long plateau, mirroring how experienced practitioners work: fix the obvious problems first, then spend the budget on incremental refinements.
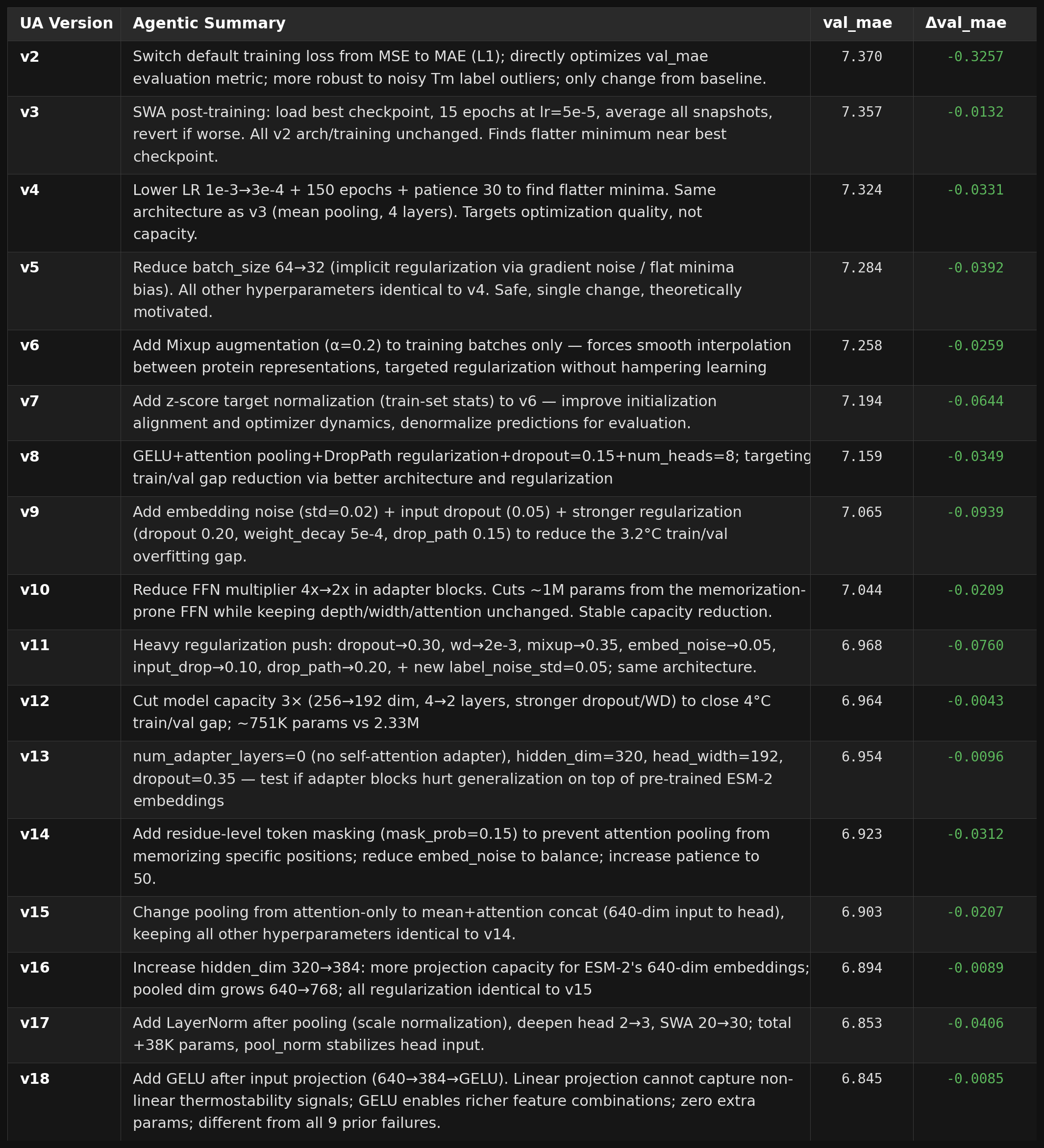
The unleashed agent (UA) received no instructions on how to approach training. It also began with intuitive changes, but instead of small adjustments it swung for the fences early. By its fourth attempt it had implemented Exponential Moving Average for weight smoothing, then followed up with Stochastic Weight Averaging for post-training. These two complementary techniques layered in quick succession. From roughly 35% to the midpoint of the run, it turned to adapter depth and hidden dimensions, eventually rewriting portions of the original adapter implementation and developing a recurring tendency to concatenate multiple pooling strategies rather than commit to one.
Around the same period, it implemented Mixup regularization, a technique from a seminal 2018 ICLR paper that interpolates training examples to smooth the decision boundary. It was cool to see that the agent identified an approach that I wasn’t originally familiar with, one that was published around the time I took my first real ML class at UC Berkeley.

Unfortunately, a bug in how we set up evaluation on Modal meant that one of the agent’s class modifications broke the evaluation pipeline — test-set metrics for later unleashed agent runs were not obtained, which is why the UA test MAE is marked with an asterisk above. This isolated UA trajectory took a much longer time to reach a plateau comparing to RA’s trajectory which likely reflect more intrinsic stochasticity than a lack of efficiency and more trajectory-level replicates may help clarify the picture.
While the numerical results are not conclusive on their own, what we find most compelling is the qualitative difference in how these methods explore the search space. The agent makes interpretable, systematic changes such as switching from MSE to Huber loss, trying orthogonal initialization, adjusting attention heads following sensible rationales. BO, on the contrary, proposes configurations that no human would articulate as a coherent strategy but that sometimes land in unexpectedly productive regions of the search space. Combining them allows the agent to set the structural direction while BO fills in the continuous details the agent would fumble through.
We want to be upfront: this is a proof-of-concept, not a definitive study. The sample sizes are small (3 replicates per approach), the search budgets are modest (100 iterations), and the dataset — while well-curated — is a limited representation of the physical complexity of protein thermostability. We cannot claim statistical significance for any pairwise comparison. What we can say is that all approaches converged to a similar performance range, that the agent-BO synthesis showed the tightest variance on the test set, and that the qualitative differences in exploration strategy are genuine and worth investigating further.
Discussion
The paradox of freedom. More freedom does not mean better results. The UA found decent architectures but consistently trended toward over-engineering despite explicit instructions to keep things simple. The restricted agent, constrained to the same 25 knobs as BO, was forced to reason within boundaries — producing targeted, efficient exploration and ablation rather than brute-force sampling, leading to an arguably faster convergence than UA or BO. Moreover, autonomy is a spectrum, not a switch. It would be exciting how varying level of freedom can impact autoresearch performance
Synergy between agents and black box optimization. Bayesian optimization does not form hypotheses about why something should work. It simply models the objective surface and proposes the next point to evaluate. This means it routinely explores regions of the search space that a reasoning agent, human or artificial, do not often explore. Agents explore like humans: interpretable, systematic, prone to overthinking. BO sweeps through the parameter space more exhaustively via a probability model. They cover each other’s blind spots. The agent provides direction; BO provides coverage. Our early results suggest this combination could potentially be useful for autonomous training in the future.
How far can agents go? Our experiment ran 100 iterations on a single small dataset with a compact model. The natural question is: what happens with 1,000 iterations, a larger backbone, or a harder problem?
First, evaluation quality. Our agents optimized against validation MAE — a single scalar that compresses everything about model quality into one number. Richer evaluation signals (calibration, subgroup performance, out-of-distribution robustness) would give agents more to reason about. Designing evaluation that is both informative and leakage-proof may be the single hardest problem in scaling autoresearch.
Second, context window limits. Our restricted agent tracked its full history of successes and summaries of failures. At 100 iterations this fits comfortably in context; at 1,000, it does not. Summarization and retrieval strategies become necessary, we are interested in understanding how gracefully an agent degrades under lossy memory through both software and hardware solutions.
Finally, human oversight. We are already approaching autonomous agents that can solve complex problems in computer science, mathematics and other theoretical disciplines. We are excited about the frontier of physical intelligence that many are building and would love to see more breakthroughs. We believe the right level of human-in-the-loop is not zero; it is the minimum needed to catch what the agent cannot catch about itself. How exactly this loop will be constructed remains to be seen.
Unsurprisingly, we do not have precise answers to these questions. But we think they are the right ones to ask — and to keep an eye on.
Appendix
Grid search gave way to random sampling, then to Bayesian optimization. Multi-fidelity methods such as BOHB compressed costs further by killing unpromising runs early. And Neural Architecture Search extended automation to structural decisions. The foundational works were introduced before the advent of GPT-1 and have matured and became widely-adopted over the last decade.